SNS Review #2: FACEBOOK and Flicker's PURGE of Different Voices
- Ryota Nakanishi (Grace)

- Jul 31, 2019
- 17 min read
Updated: Apr 5, 2024

FREEDOM OF EXPRESSION MUST BE RESPECTED
Important FACEBOOK and Flicker

The US first amendment clearly stated that ''Amendment I
Congress shall make no law respecting an establishment of religion, or prohibiting the free exercise thereof; or abridging the freedom of speech, or of the press; or the right of the people peaceably to assemble, and to petition the government for a redress of grievances.'' (1)
However US tech. giants are recently purging different voices more harshly than ever. As the result, there are increasing numbers of complaints against their social network service users around the world.
Some US tech giants are managing their different language sites in some countries or regions where they don't even have their physical offices. The internet operations are actually affecting too many people's lives without borders. This is why cross border or borderless regulations for these tech giants are necessary like increasing corporate taxation.
On Facebook violations, Germany and US these respected countries and legitimate governments bravely started punishing the giant in 2019.
FACTS
1.Germany's Federal Office of Justice (BfJ) on Tuesday fined US social media giant Facebook €2 million ($2.3 million) for underreporting the number of complaints it had received about illegal content on its platform.
The fine was levied for infractions against Germany's internet transparency law known as NetzDG.
The law requires companies like Facebook and Twitter to remove posts that contain hate speech or incite violence within 24 hours or face fines as high as €50 million. Social media companies are also required to file reports on their progress every six months.
Read more: Germany implements new internet hate speech crackdown
Skewing the facts
Justice Minister Christine Lambrecht accused the company of skewing the extent of such violations by selectively reporting complaints.
Lambrecht said it was exceedingly difficult for a user to complain to Facebook about posts that violate NetzDG. She added that by comparison, it was far easier to complain about posts that violate the site's softer community standards.
But Lambrecht said that Facebook's decision to only tally the NetzDG complaints meant the total number was artificially low.
That selective reporting led Facebook to cite a total of 1,704 complaints from January 1, 2018 to June 30, 2018. That number was significantly lower than those that YouTube (215,000) and Twitter (265,000) reported for the full year.
The Office of Justice addressed that problem, saying, "The BfJ assumes that the number of complaints received via the widely known flagging channel is considerable and that what is presented in the published report is therefore incomplete."
Read more: Facebook slams proposed German 'anti-hate speech' social media law
Strict laws governing online speech
NetzDG, which went into effect on January 1, 2018, is among the strictest in the world governing privacy and online speech. It outlaws anti-Semitic speech as well as hateful or inciting speech directed at persons or groups on the grounds of religion or ethnicity.
Facebook has desperately attempted to clean up its image regarding transparency in the wake of a number of scandals involving elections in the US, UK, and the Philippines. The company has said it will review Tuesday's decision and may appeal it.
Facebook said: "We want to remove hate speech as quickly and effectively as possible and work to do so. We are confident our published NetzDG reports are in accordance with the law, but as many critics have pointed out, the law lacks clarity."
— js/amp (AFP, AP, Reuters) (2)
URL:
2. The Federal Trade Commission announced on Wednesday that Facebook agreed to pay a record-breaking $5 billion fine over privacy violations. The penalty follows an investigation into the Cambridge Analytica data-sharing scandal.
“The $5 billion penalty against Facebook is the largest ever imposed on any company for violating consumers’ privacy and almost 20 times greater than the largest privacy or data security penalty ever imposed worldwide,” the FTC said in a press release. It added that “it is one of the largest penalties ever assessed by the US government for any violation.”
According to FTC Chairman Joe Simons, “Despite repeated promises to its billions of users worldwide that they could control how their personal information is shared, Facebook undermined consumers’ choices.”
Facebook has also agreed to pay an additional $100 million to settle allegations that it misled investors about the seriousness of the misuse of users’ data, the Securities and Exchange Commission (SEC) said.
The FTC first started probing Facebook in March 2018 after reports that the social network allowed as many as 87 million users’ data to fall into the possession of political consulting firm Cambridge Analytica.
Allowing access to the data was a violation of a 2012 FTC consent decree.
Despite the fact that the $5 billion fine is the biggest in FTC history, far bigger than the $22 million fine levied against Google in 2012, critics have argued that the penalty is too low. The fine has been dubbed an “embarrassing joke,” a “parking ticket,” and a “sweetheart deal.”
The ‘largest’ FTC fine in US history represents basically a month of Facebook’s revenue. The company had $15 billion in revenue last quarter and $22 billion in profit in 2018.
US Senator Richard Blumenthal, a Democrat from Connecticut, called the settlement “a fig leaf” that offers “no accountability for top executives.”
“By relying on a monetary fine to deter Facebook, the FTC has failed to heed history’s lessons. Facebook has already written this penalty down as a one-time-cost in return for the extraordinary profits reaped from a decade of data misuse,” Blumenthal was quoted as saying by Reuters.
There was also criticism levelled at the FTC for not holding Facebook founder and CEO Mark Zuckerberg personally responsible. Democratic FTC Commissioner Rebecca Slaughter said the trade commission should have taken Zuckerberg to court.
— RT (3)
URL:
Comment
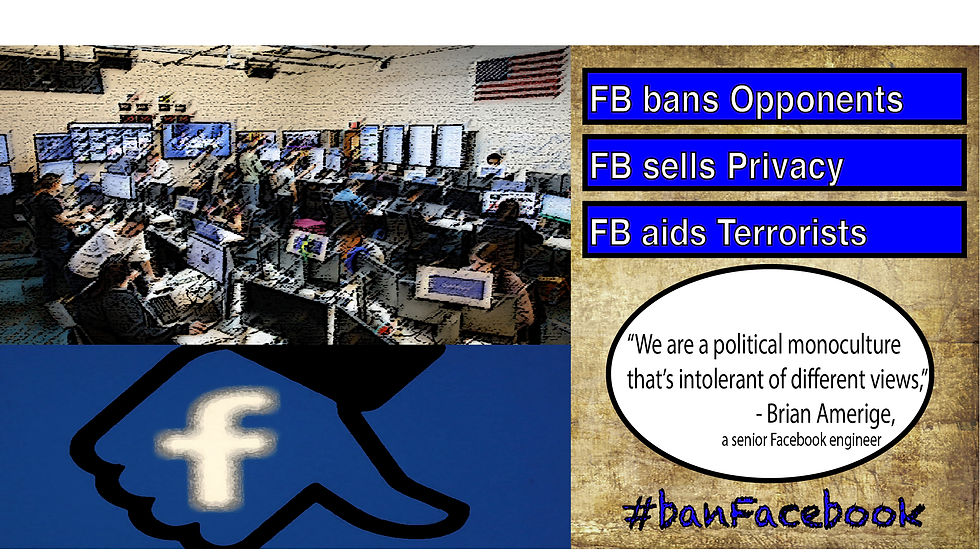
For Facebook's violations of its notoriously biased censorship on hate speeches and violations of privacy of its users must be punished by respected governments who are determined to protect their own people and other countries' users. Nothing bad for users if these governments take necessary actions against uncontrollable social network giants like this one.
Flicker

Flicker is now part of US company which is seemed as photo sharing social network service of US however its users are complaining about their purges which similar to other SNS like Facebook. Moreover, Flicker is the potential violator of users' privacy by providing its uploaded photos for unspeakable facial recognition surveillance without any permission and communications of the users. Like other US and its allies' SNS companies, they are highly biased on political issues including Hong Kong's extradition bill issue. At present, Flicker's scandal news is limited but actual news and many complaints we can read online.
Facts
1. Facial recognition can log you into your iPhone, track criminals through crowds and identify loyal customers in stores.
The technology — which is imperfect but improving rapidly — is based on algorithms that learn how to recognize human faces and the hundreds of ways in which each one is unique.
To do this well, the algorithms must be fed hundreds of thousands of images of a diverse array of faces. Increasingly, those photos are coming from the internet, where they’re swept up by the millions without the knowledge of the people who posted them, categorized by age, gender, skin tone and dozens of other metrics, and shared with researchers at universities and companies.
As the algorithms get more advanced — meaning they are better able to identify women and people of color, a task they have historically struggled with — legal experts and civil rights advocates are sounding the alarm on researchers’ use of photos of ordinary people. These people’s faces are being used without their consent, in order to power technology that could eventually be used to surveil them.
That’s a particular concern for minorities who could be profiled and targeted, the experts and advocates say.
“This is the dirty little secret of AI training sets. Researchers often just grab whatever images are available in the wild,” said NYU School of Law professor Jason Schultz.
The latest company to enter this territory was IBM, which in January released a collection of nearly a million photos that were taken from the photo hosting site Flickr and coded to describe the subjects’ appearance. IBM promoted the collection to researchers as a progressive step toward reducing bias in facial recognition.
But some of the photographers whose images were included in IBM’s dataset were surprised and disconcerted when NBC News told them that their photographs had been annotated with details including facial geometry and skin tone and may be used to develop facial recognition algorithms. (NBC News obtained IBM’s dataset from a source after the company declined to share it, saying it could be used only by academic or corporate research groups.)
“None of the people I photographed had any idea their images were being used in this way,” said Greg Peverill-Conti, a Boston-based public relations executive who has more than 700 photos in IBM’s collection, known as a “training dataset.”
“It seems a little sketchy that IBM can use these pictures without saying anything to anybody,” he said.
John Smith, who oversees AI research at IBM, said that the company was committed to “protecting the privacy of individuals” and “will work with anyone who requests a URL to be removed from the dataset.”
Despite IBM’s assurances that Flickr users can opt out of the database, NBC News discovered that it’s almost impossible to get photos removed. IBM requires photographers to email links to photos they want removed, but the company has not publicly shared the list of Flickr users and photos included in the dataset, so there is no easy way of finding out whose photos are included. IBM did not respond to questions about this process.
To see if your Flickr photos are part of the dataset, enter your username in a tool NBC News created based on the IBM dataset:
IBM says that its dataset is designed to help academic researchers make facial recognition technology fairer. The company is not alone in using publicly available photos on the internet in this way. Dozens of other research organizations have collected photos for training facial recognition systems, and many of the larger, more recent collections have been scraped from the web.
Some experts and activists argue that this is not just an infringement on the privacy of the millions of people whose images have been swept up — it also raises broader concerns about the improvement of facial recognition technology, and the fear that it will be used by law enforcement agencies to disproportionately target minorities.
“People gave their consent to sharing their photos in a different internet ecosystem,” said Meredith Whittaker, co-director of the AI Now Institute, which studies the social implications of artificial intelligence. “Now they are being unwillingly or unknowingly cast in the training of systems that could potentially be used in oppressive ways against their communities.”
In the early days of building facial recognition tools, researchers paid people to come to their labs, sign consent forms and have their photo taken in different poses and lighting conditions. Because this was expensive and time consuming, early datasets were limited to a few hundred subjects.
With the rise of the web during the 2000s, researchers suddenly had access to millions of photos of people.
“They would go into a search engine, type in the name of a famous person and download all of the images,” said P. Jonathon Phillips, who collects datasets for measuring the performance of face recognition algorithms for the National Institute of Standards and Technology. “At the start these tended to be famous people, celebrities, actors and sports people.”
As social media and user-generated content took over, photos of regular people were increasingly available. Researchers treated this as a free-for-all, scraping faces from YouTube videos, Facebook, Google Images, Wikipedia and mugshot databases.
Academics often appeal to the non-commercial nature of their work to bypass questions of copyright. Flickr became an appealing resource for facial recognition researchers because many users published their images under “Creative Commons” licenses, which means that others can reuse their pictures without paying license fees. Some of these licenses allow commercial use.
To build its Diversity in Faces dataset, IBM says it drew upon a collection of 100 million images published with Creative Commons licenses that Flickr’s owner, Yahoo, released as a batch for researchers to download in 2014. IBM narrowed that dataset down to about 1 million photos of faces that have each been annotated, using automated coding and human estimates, with almost 200 values for details such as measurements of facial features, pose, skin tone and estimated age and gender, according to the dataset obtained by NBC News.
It’s a single case study in a sea of datasets taken from the web. According to Google Scholar, hundreds of academic papers have been written on the back of these huge collections of photos — which have names like MegaFace, CelebFaces and Faces in the Wild — contributing to major leaps in the accuracy of facial recognition and analysis tools. It was difficult to find academics who would speak on the record about the origins of their training datasets; many have advanced their research using collections of images scraped from the web without explicit licensing or informed consent.
The researchers who built those datasets did not respond to requests for comment.
IBM released its collection of annotated images to other researchers so that it can be used to develop “fairer” facial recognition systems. That means systems can more accurately identify people of all races, ages and genders.
“For the facial recognition systems to perform as desired, and the outcomes to become increasingly accurate, training data must be diverse and offer a breadth of coverage,” said IBM’s John Smith, in a blog post announcing the release of the data.
The dataset does not link the photos of people’s faces to their names, which means any system trained to use the photos would not be able to identify named individuals. But civil liberty advocates and tech ethics researchers have still questioned the motives of IBM, which has a history of selling surveillance tools that have been criticized for infringing on civil liberties.
For example, in the wake of the 9/11 attacks, the company sold technology to the New York City police department that allowed it to search CCTV feeds for people with particular skin tones or hair color. IBM has also released an “intelligent video analytics” product that uses body camera surveillance to detect people by “ethnicity” tags, such as Asian, black or white.
IBM said in an email that the systems are “not inherently discriminatory,” but added: “We believe that both the developers of these systems and the organizations deploying them have a responsibility to work actively to mitigate bias. It’s the only way to ensure that AI systems will earn the trust of their users and the public. IBM fully accepts this responsibility and would not participate in work involving racial profiling.”
Today, the company sells a system called IBM Watson Visual Recognition, which IBM says can estimate the age and gender of people depicted in images and, with the right training data, can be used by clients to identify specific people from photos or videos.
NBC News asked IBM what training data IBM Watson used for its commercial facial recognition abilities, pointing to a company blog post that stated that Watson is “transparent about who trains our AI systems, what data was used to train those systems.” The company responded that it uses data “acquired from various sources” to train its AI models but does not disclose this data publicly to “protect our insights and intellectual property.”
IBM said both in public statements and directly to NBC News that the Diversity in Faces dataset is purely for academic research and won’t be used to improve the company’s commercial facial recognition tools. This seems to conflict with the company’s assertion in January in promotional materials that the release of the dataset is a direct response to research by MIT’s Joy Buolamwini that showed that IBM’s commercial facial recognition technology was much worse at accurately identifying darker-skinned women than lighter-skinned men.
When asked about this conflict, and particularly about how the Diversity in Faces dataset might have a real-world impact on reducing bias if IBM is not using it in commercial facial recognition products, Smith said in an email that the “scientific learnings on facial diversity will advance our understanding and allow us to create more fair and accurate systems in practice.”
“We recognize that societal bias is not necessarily something we can fully tackle with science, but our aim is to address mathematical and algorithmic bias,” Smith said.
Experts note that the distinction between the research wings and commercial operations of corporations such as IBM and Facebook is a blurry one. Ultimately, IBM owns any intellectual property developed by its research unit.
Even when algorithms are developed by academic researchers using non-commercial datasets, those algorithms are often later used by businesses, said Brian Brackeen, former CEO of the facial recognition company Kairos.
As an analogy, he said, “think of it as the money laundering of facial recognition. You are laundering the IP and privacy rights out of the faces.”
IBM said it would not use the Diversity in Faces dataset in this way.
An Austrian photographer and entrepreneur, Georg Holzer, uploaded his photos to Flickr to remember great moments with his family and friends, and he used Creative Commons licenses to allow non-profits and artists to use his photos for free. He did not expect more than 700 of his images to be swept up to study facial recognition technology.
“I know about the harm such a technology can cause,” he said over Skype, after NBC News told him his photos were in IBM’s dataset. “Of course, you can never forget about the good uses of image recognition such as finding family pictures faster, but it can also be used to restrict fundamental rights and privacy. I can never approve or accept the widespread use of such a technology.”
Holzer was concerned that a company like IBM — even its research division — had used photos he published under a non-commercial license.
“Since I assume that IBM is not a charitable organization and at the end of the day wants to make money with this technology, this is clearly a commercial use,” he said.
Dolan Halbrook, who is based in Portland, Oregon, and has 452 photos in the dataset, agreed that IBM should have asked his permission.
“I'm annoyed at them being used without prior notification and a chance to review which ones would be included,” Halbrook said. “I'm ambivalent about improving the technology itself.”
Other photographers were glad to hear that their images may be used to advance the field of facial recognition.
“Facial recognition is one of those things we can’t uninvent, so having a reliable system is better than one that generates errors and false identifications,” said Neil Moralee, a food consultant and photographer based in the U.K. who specializes in portraits.
Guillaume Boppe from Switzerland agreed. “If the pictures of faces I shot are helping AI to improve, reducing false detection and ultimately improving global safety, I’m fine with it,” he said
IBM does offer an opt-out model of sorts: People can contact IBM with individual links to photographs they want removed from the dataset — either ones they have taken or ones they are featured in — and IBM says it will remove them, according to its privacy notice.“ However, there’s no easy way to know if you are featured in the dataset, and even if you find out that you are, IBM said it will not remove photos on the basis of your Flickr user ID unless you also have links to each of the photographs.
When NBC News alerted one photographer, who asked not to be named for privacy reasons, that more than 1,000 of his photos were included in IBM’s dataset, he tried to opt out by sending IBM his Flickr user ID. IBM told him that none of his photos were in the dataset, according to an email viewed by NBC News. When NBC News shared specific links to some of his photos in IBM’s dataset, the company blamed an “indexing bug” for its initial inability to confirm that his images were included. After more than a week, IBM confirmed it had removed the four photos he had provided links to. According to NBC News’ analysis, he still has 1,001 photos in the dataset.
Smith, of IBM, said in a statement that all URL removal requests had been completed.
Even once an image is removed from the IBM dataset, it won’t be removed from the versions of the dataset already shared with research partners (about 250 organizations have requested access so far), IBM said. Nor will it be removed from the underlying Flickr dataset.
For those caught up in IBM’s dataset or others like it, this makes the notion of opting out seem hopeless.
There may, however, be legal recourse in some jurisdictions thanks to the rise of privacy laws acknowledging the unique value of photos of people’s faces. Under Europe’s General Data Protection Regulation, photos are considered “sensitive personal information” if they are used to confirm an individual’s identity. Residents of Europe who don’t want their data included can ask IBM to delete it. If IBM doesn’t comply, they can complain to their country’s data protection authority, which, if the particular photos fall under the definition of “sensitive personal information,” can levy fines against companies that violate the law.
In the U.S., some states have laws that could be relevant. Under the Illinois Biometric Information Privacy Act, for example, it can be a violation to capture, store and share biometric information without a person’s written consent. According to the act, biometric information includes fingerprints, iris scans and face geometry.
"This is the type of mass collection and use of biometric data that can be easily abused, and appears to be taking place without the knowledge of those in the photos,” said Jay Edelson, a Chicago-based class-action lawyer currently suing Facebook for its use of facial recognition tools.
So far neither of these laws has been rigorously tested.
IBM declined to comment on the laws.
Aside from the privacy issues, a bigger question remains: Are more accurate facial recognition systems actually “fairer”? And is it possible for facial recognition to be fair at all?
“You’ve really got a rock-and-a-hard-place situation happening here,” said Woody Hartzog, a professor of law and computer science at Northeastern University. “Facial recognition can be incredibly harmful when it’s inaccurate and incredibly oppressive the more accurate it gets.”
While there are benign uses for facial recognition, it can also be used to surveil and target people of color and other vulnerable and minority communities. Facial recognition databases of mugshots are more likely to include African-Americans, Latinos and immigrants, since those groups are targeted by biased policing practices, civil rights groups say. This means that those people are far more “findable” by facial recognition technology, even if they were wrongly arrested when their mugshot was taken.
The use of facial recognition surveillance systems by law enforcement is so controversial that a coalition of more than 85 racial justice and civil rights groups have called for tech companies to refuse to sell the technology to governments. These groups argue that the technology exacerbates “historical and existing bias” that harms communities that are already “over-policed and over-surveilled.”
“These systems are being deployed in oppressive contexts, often by law enforcement,” said Whittaker, of the AI Now Institute, “and the goal of making them better able to surveil anyone is one we should look at very skeptically.”
CORRECTION (March 12, 2019, 8:18 p.m. ET): An earlier version of this article incorrectly described Brian Brackeen’s position at Kairos. He is the former CEO, not the current one.
CLARIFICATION (March 17, 2019, 11:25 a.m. ET): An earlier version of this article said IBM accessed Flickr photos by scraping them from Flickr’s site, implying that they were taken from the live web site. IBM says it took the photos from a collection Flickr released several years ago of photos taken from its own databases.
—Olivia Solon (4)
URL:
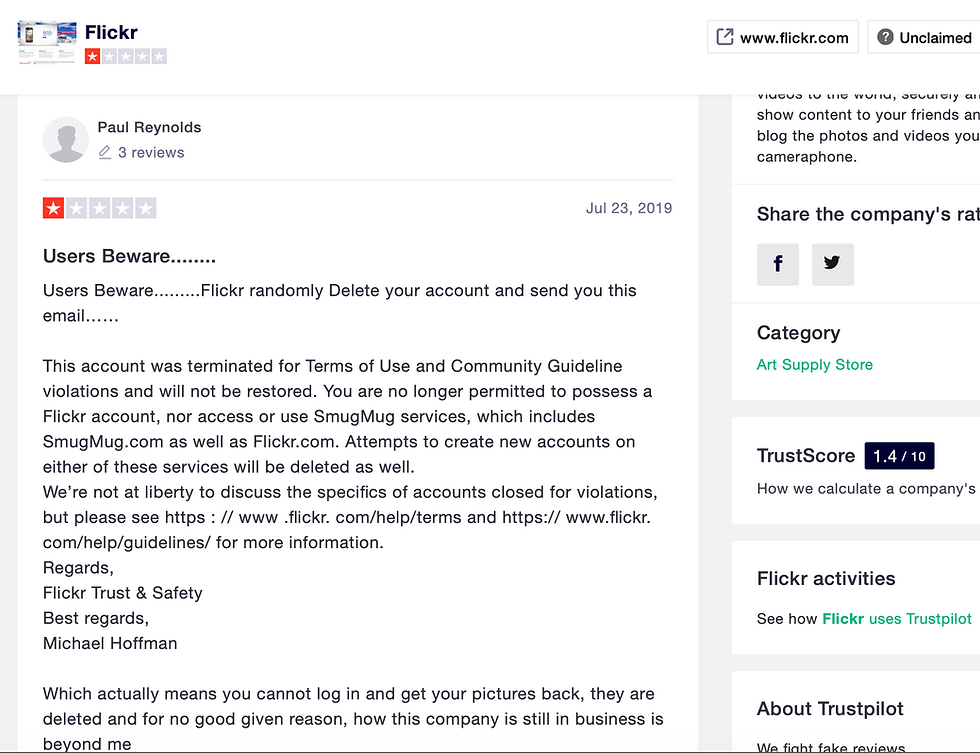
2. The User Reviewing Site, Trustpilot shows some recent complaints from Flicker users. Typical complaint is about their Flickr Trust & Safety staff Michael Hoffman who is recently deleting and blocking free account users without any communications, any precautions, any explanations, and any factual proofs. It is a clear violation of freedom of expression and the worst kind of customer service which typical in these US tech giants. A bad example of uncivilised behaviour.
3. Forcible measure against free account users is confirmed at their Help Forum, One user excellent start claimed that Flicker secretly blocked access to their accounts and forced them to purchase Flicker Pro accounts. Unlike what main stream media reported, Flicker did not just delete exceeded number of photos from free account users. In fact, Flicker forced them to purchase advanced service account which called Flicker Pro. by blocking their assess to the accounts.

(6)
URL:
4. Even paid accounts are not safe. Like one user ccmanla's complaint against Flicker's reckless deletions that done without any explanations and any communications.

(7)
URL:
Comment
First of all, deletion and blocking with no precautions, no communications, no explanations, no factual proofs shown for users are fundamental problems like what Flickr Trust & Safety staff Michael Hoffman recently so eagerly doing for his own individual interests and performance evaluation at the company.
Their typically biased censorship and forcing measures against its users and consumers are violating human rights. The worst kind of customer service is also done by this kind of staff Michael Hoffman.
Many victims of this kind of terrible corporate acts must place your complaints publicly and if possible victims should file a law suit against Flickr Trust & Safety staff Michael Hoffman and Flicker.
Beside this problematic groundless censorship and its forcible measures against users and different voices, there is also more serious concern about their use of uploaded photos for facial recognition surveillance without any permissions.
These issues only proved that Flicker is a possible violator of privacy and the next SNS company to be blamed and punished by respected governments and its users like Facebook.
The battle for human rights and freedom of expression will continue.
Notes
(1) First Amendment, Legal Information Institute, https://www.law.cornell.edu/constitution/first_amendment accessed on July 31, 2019.
(2) Js/amp (AFP, AP, Reuters), Germany fines Facebook for underreporting hate speech complaints, DW.Com, 02.07.2019,
https://www.dw.com/en/germany-fines-facebook-for-underreporting-hate-speech-complaints/a-49447820 accessed on July 31, 2019.
(3) Facebook agrees to pay record $5bn fine over privacy violations, critics call it a ‘parking ticket,' RT, Published time: 24 Jul, 2019 14:41; Edited time: 24 Jul, 2019 15:04,
https://www.rt.com/business/464958-facebook-record-fine-privacy/ accessed on July 31, 2019.
(4) Olivia Solon, Facial recognition's 'dirty little secret': Millions of online photos scraped without consent, NBC News, March 12, 2019, 4:32 PM GMT+8 / Updated March 17, 2019, 11:25 PM GMT+8,
https://www.nbcnews.com/tech/internet/facial-recognition-s-dirty-little-secret-millions-online-photos-scraped-n981921#anchor-Fewoptionsforoptingout accessed on July 31, 2019.
(5) Paul Raynolds, Users Beware........, Trustpilot, July 23, 2019,
https://www.trustpilot.com/review/www.flickr.com accessed on July 31, 2019.
(6) excellent start, Flickr is blocking access to my account unless I agree to let them delete photos., Flicker The Help Forum, June 30, 2019,
https://www.flickr.com/help/forum/en-us/72157709339982951/ accessed on July 31, 2019.
(7) ccmanla, [Closed] Deleted for no reason = FRUSTRATED, Flicker The Help Forum, July 8, 2008,
https://www.flickr.com/help/forum/76492/?search=nauseum accessed on July 31, 2019.





Comments